What is the JCC Erratum?
It is a bug (“errata”) that affects pretty much all Intel Core processors (from 2nd generation “Sandy Bridge” SNB to 10th generation “Comet Lake” CML) but not the next-generation Core (10th generation “Ice Lake” ICL and later). JCC stands for “Jump Conditional Code”, i.e. conditional instructions (compare/test and jump) that are very common in all software. Intel has indicated that some conditions may cause “unpredictable behaviour” that perhaps can be “weaponised” thus it had to be patched through microcode (firmware). This affects all code, privileged/kernel as well as user mode programs.
Unfortunately the patch can result in somewhat significant performance regression since any “jumps” that span 32-byte boundary (not uncommon) now cannot be cached (by the “decoded iCache (instruction cache)” aka “DSB”). The DSB caches decoded instructions so they don’t need to be decoded again when the same code executes again (pretty likely).
This code is now forced to use the “legacy (execution) pipeline” (that is not fast as the “modern (execution) pipeline(s)”) that is naturally much slower and also incurs a time penalty (latency) switching between pipelines.
Can these performance penalties be reduced?
By rebuilding software (if possible i.e. source code is available) with updated tools (compilers, assemblers) this condition can be avoided by aligning “jumps” to 32-byte boundaries. This way the mitigation will not be engaged, thus the performance regression can be avoided. However, everything must be rebuilt – programs, libraries (DLL, object), device drivers and so on – old software in object form cannot be “automagically” fixed at run-time.
The alignment is done though “padding” with dummy code (“no-op” or superfluous encodings) and thus does increase code size aka “bloat”. Fortunately the on average the code size increases by 3-5% which is manageable.
What about JIT CPU-agnostic byte-code (.Net, Java)?
JIT compiled code (such as .Net, Java, etc.) will require engine (JVM/CLR) updates but will not require rebuilding. Current engines and libraries are not likely to be updated – thus this will require new versions (e.g. Java 8/11/12 to Java 13) that will need to be tested for full compatibility.
What software can and has been updated so far?
Open-source software (“Linux”, “FreeBSD”, etc.) can easily be rebuild as the source-code (except proprietary blobs) is available. Current versions of main distributions have not been updated so far but future versions are likely to be so, starting with 2020 updates.
Microsoft has indicated that Windows 20/04 has been rebuilt and future versions are likely to be updated, naturally all older versions of client & server (19XX, 18XX, etc.) will naturally not be updated. Thus servers rather than clients are more likely to be affected by this change as not likely to be updated until the next major long-term refresh.
What has been updated in Sandra?
Sandra 20/20/8 – aka Release 8 / version 30.50 – and later has been built with updated tools (Visual Studio 2019 latest version, ML/MASM, TASM assemblers) and JCC mitigation enabled. This includes all benchmarks including assembler code (x86 and x64). Note that assembler code needs to be modified by hand by adding alignment instructions where necessary.
We are still analysing and instrumenting the benchmarks on a variety of processors and are continuing to optimise the code where required.
To compare against the other processors, please see our other articles:
- Benchmarks of JCC Erratum Mitigation – AMD CPUs
- Intel Core Gen11 TigerLake ULV (i7-1165G7) – CPU AVX512 Performance
- Intel Core Gen10 IceLake ULV (i7-1065G7) – CPU AVX512 Performance
- Intel Core Gen10 CometLake ULV (i7-10510U) – CPU Performance
Hardware Specifications
We are comparing common Intel Core/X architectures (gen 7, 8, 9) that are affected by the JCC erratum and microcode mitigating it has been installed. In this article we test the effect on Intel hardware only. See the other article for the effect on AMD hardware.
| CPU Specifications | Intel i9-7900X (10C/20T) (Skylake-X) | Intel i9-9900K (8C/16T) (CoffeeLake-R) | Intel i7-8700K (6C/12T) (Coffeelake) | Comments | |
| Cores (CU) / Threads (SP) | 10C / 20T | 8C / 16T | 6C / 12T | Various code counts. | |
| Special Instruction Sets |
AVX512 | AVX2/FMA | AVX2/FMA | 512 or 256-bit. | |
| Microcode no JCC |
5E | Ax, Bx | Ax, Bx | ||
| Microcode with JCC |
65 | Dx | Cx | More revisions. | |
Native Performance
We are testing native arithmetic, SIMD and cryptography performance using the highest performing instruction sets (AVX512, AVX2/FMA, AVX, etc.).
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest Intel drivers. 2MB “large pages” were enabled and in use. Turbo / Boost was enabled on all configurations. Latest JCC-enabling microcode has been installed either through the latest BIOS or Windows itself.
| Native Benchmarks | Intel i9-7900X (10C/20T) (Skylake-X) | Intel i9-9900K (8C/16T) (CoffeeLake-R) | Intel i7-8700K (6C/12T) (Coffeelake) | Comments | ||
 |
||||||
 |
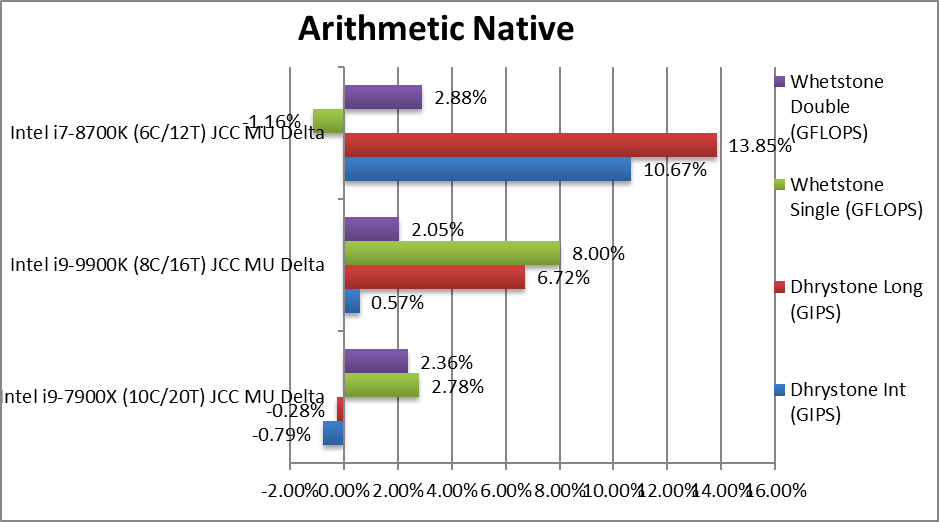
Native Dhrystone Integer (GIPS) | -0.79% | +0.57% | +10.67% | Except CFL gaining 10%, little variation. | |
|
Native Dhrystone Long (GIPS) | -0.28% | +6.72% | +13.85% | With a 64-bit integer – nothing much changes. | |
|
Native FP32 (Float) Whetstone (GFLOPS) | +2.78% | +8% | -1.16% | With floating-point, CFL-R gains 8%. | |
|
Native FP64 (Double) Whetstone (GFLOPS) | +2.36% | +2.05% | +2.88% | With FP64 we see a 3% improvement. | |
| While CFL (8700K) gains 10% in legacy integer workload and CFL-R (9900K) gains 8% in legacy floating-point workload, there are only minor variations. It seems CFL-series shows more variability than the older SKL series. | ||||||
 |
||||||
 |
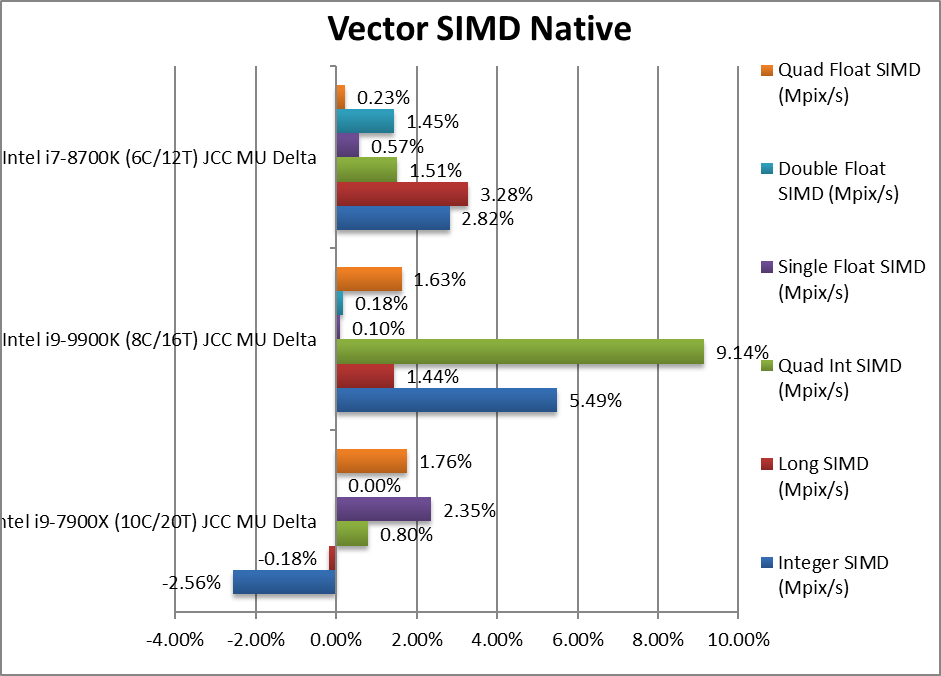
Native Integer (Int32) Multi-Media (Mpix/s) | -2.56% | +5.49% | +2.82% | With AVX2 integer CFL/R both gain 3-5%. | |
|
Native Long (Int64) Multi-Media (Mpix/s) | -0.18% | +1.44% | +3.28% | With a 64-bit AVX2 integer we see smaller improvement. | |
|
Native Quad-Int (Int128) Multi-Media (Mpix/s) | +0.8% | +9.14% | +1.51% | A tough test using long integers to emulate Int128 without SIMD, CFL-R gains 9%. | |
|
Native Float/FP32 Multi-Media (Mpix/s) | +2.35% | +0.1% | +0.57% | Floating-point shows minor variation | |
|
Native Double/FP64 Multi-Media (Mpix/s) | 0% | +0.18% | +1.45% | Switching to FP64 SIMD nothing much changes. | |
|
Native Quad-Float/FP128 Multi-Media (Mpix/s) | +1.75% | +1.63% | +0.23% | A heavy algorithm using FP64 to mantissa extend FP128 minor changes. | |
| With heavily vectorised SIMD workloads (written in assembler) we see smaller variation, altough both CFL/R processors are marginally faster (~3%). Unlike high-level code (C/C++, etc.) assembler code is less dependent on the tools used for building – thus shows less variability across versions. | ||||||
 |
||||||
 |
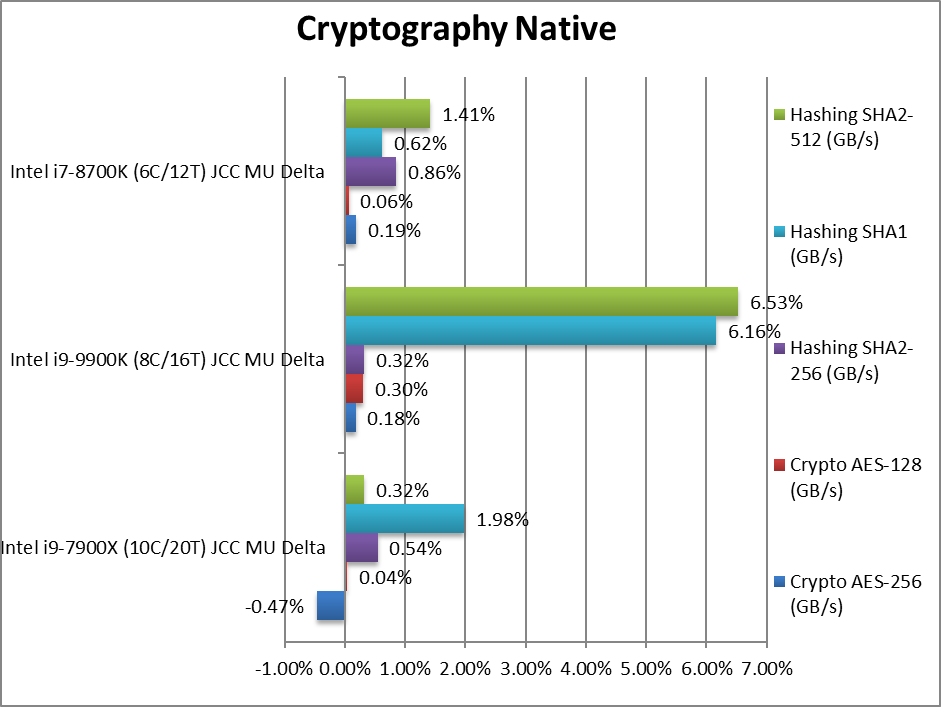
Crypto AES-256 (GB/s) | -0.47% | +0.18% | +0.19% | Memory bandwidth rules here thus minor variation. | |
|
Crypto AES-128 (GB/s) | +0.04% | +0.30% | +0.06% | No change with AES128. | |
|
Crypto SHA2-256 (GB/s) | +0.54% | +0.32% | +0.86% | No change with SIMD code. | |
|
Crypto SHA1 (GB/s) | +1.98% | +6.16% | +0.62% | Less compute intensive SHA1 does not change things. | |
|
Crypto SHA2-512 (GB/s) | +0.32% | +6.53% | +1.41% | 64-bit SIMD does not change results. | |
| The memory sub-system is crucial here, thus we see the least variation in performance; even SIMD workloads are not affected much. Again we see CFL-R showing the biggest gain while SKL-X pretty much constant. | ||||||
 |
||||||
 |
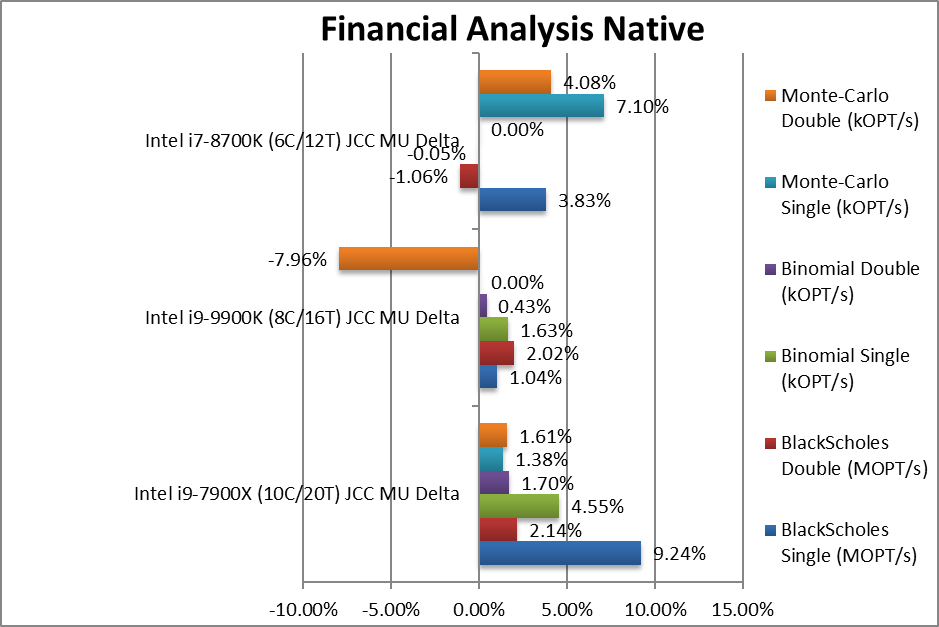
Black-Scholes float/FP32 (MOPT/s) | +9.26% | +1.04% | +3.83% | B/S does not use much shared data and here SKL-X gains large. | |
|
Black-Scholes double/FP64 (MOPT/s) | +2.14% | +2.02% | -1.06% | Using FP64 code variability decreases. | |
|
Binomial float/FP32 (kOPT/s) | +4.55% | +1.63% | -0.05% | Binomial uses thread shared data thus stresses the cache & memory system. | |
|
Binomial double/FP64 (kOPT/s) | +1.7% | +0.43% | 0% | With 64-bit code we see less delta. | |
|
Monte-Carlo float/FP32 (kOPT/s) | +1.38% | 0% | +7.1% | Monte-Carlo also uses thread shared data but read-only thus reducing modify pressure on the caches. | |
|
Monte-Carlo double/FP64 (kOPT/s) | +1.61% | -7.96% | +4.08% | Switching to FP64 we see less variability | |
| With non-SIMD financial workloads, we see bigger differences with either CFL or SKL-X showing big improvements in some tests but not in others. Overall it shows that, perhaps the tools still need some work as the gains/losses are not consistent. | ||||||
 |
||||||
 |
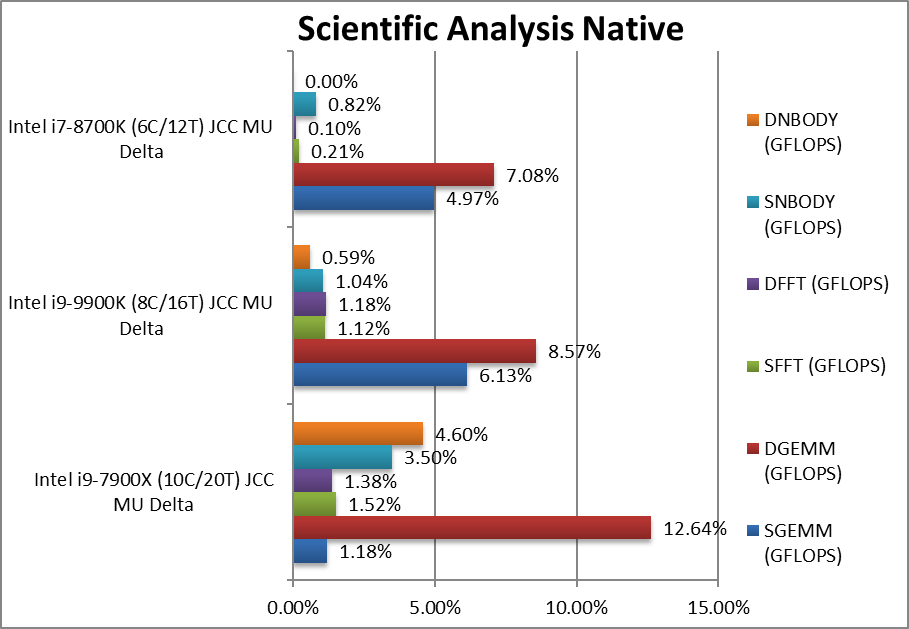
SGEMM (GFLOPS) float/FP32 | +1.18% | +6.13% | +4.97% | In this tough vectorised workload CFL/R gains most. | |
|
DGEMM (GFLOPS) double/FP64 | +12.64% | +8.58% | +7.08% | With FP64 vectorised all CPUs gain big. | |
|
SFFT (GFLOPS) float/FP32 | +1.52% | +1.12% | +0.21% | FFT is also heavily vectorised but memory dependent we see little variation. | |
|
DFFT (GFLOPS) double/FP64 | +1.38% | +1.18% | +0.10% | With FP64 code, nothing much changes. | |
|
SNBODY (GFLOPS) float/FP32 | +3.5% | +1.04% | +0.82% | N-Body simulation is vectorised but with more memory accesses. | |
|
DNBODY (GFLOPS) double/FP64 | +4.6% | +0.59% | 0% | With FP64 code SKL-X improves. | |
| With highly vectorised SIMD code (scientific workloads), SKL-X finally improves while CFL/R does not change much – although this could be due to optimisations elsewhere. Some algorithms that are completely memory latency/bandwidth dependent thus will not be affected by JCC. | ||||||
 |
||||||
 |
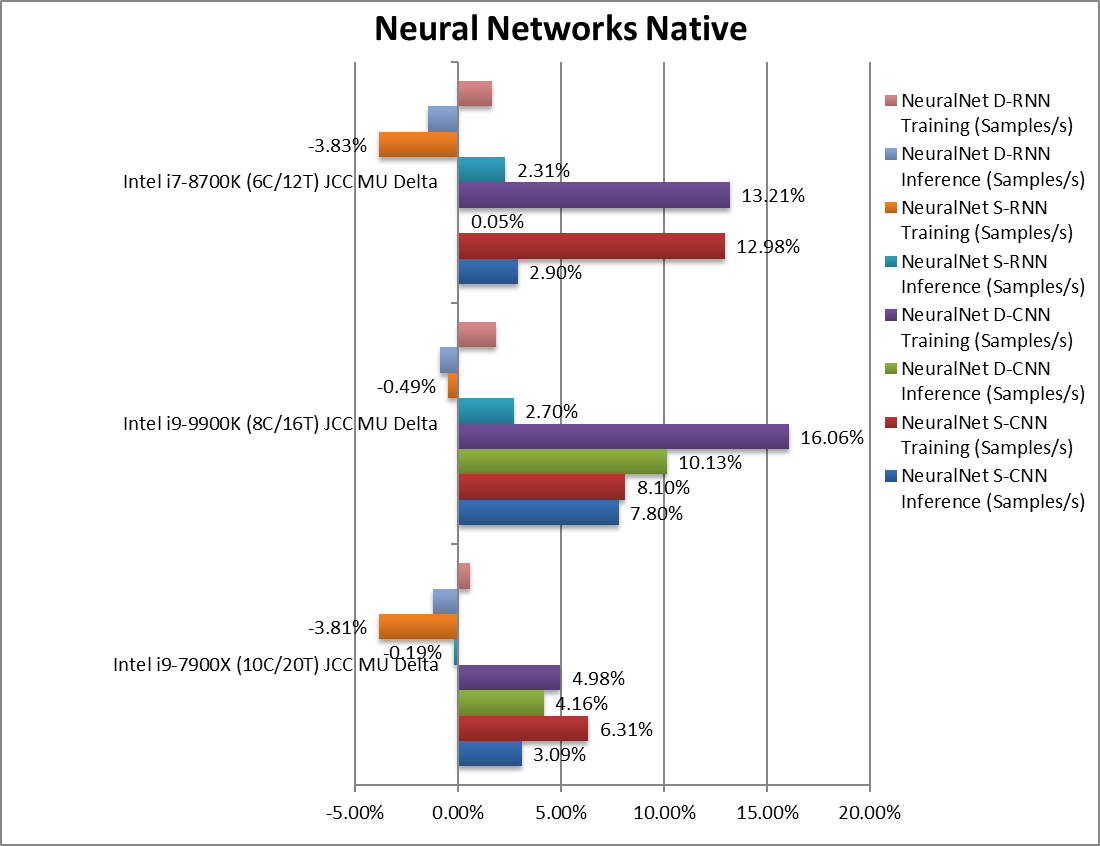
NeuralNet CNN Inference (Samples/s) | +3.09% | +7.8% | +2.9% | We see a decent improvement in inference of 3-8%. | |
|
NeuralNet CNN Training (Samples/s) | +6.31% | +8.1% | +12.98% | Training seems to improve even more. | |
 |
NeuralNet RNN Inference (Samples/s) | -0.19% | +2.7% | +2.31 | RNN inference shows little variation. | |
|
NeuralNet RNN Training (Samples/s) | -3.81% | -0.49% | -3.83% | Strangely all CPUs are slower here. | |
| Despite heavily use of vectorised SIMD code, using intrinsics (C++) rather than assembler can result in larger performance variation from one version of compiler (and code-generation options) to the next. While some tests do gain, others show regressions which likely will be addressed by future versions. | ||||||
 |
||||||
|
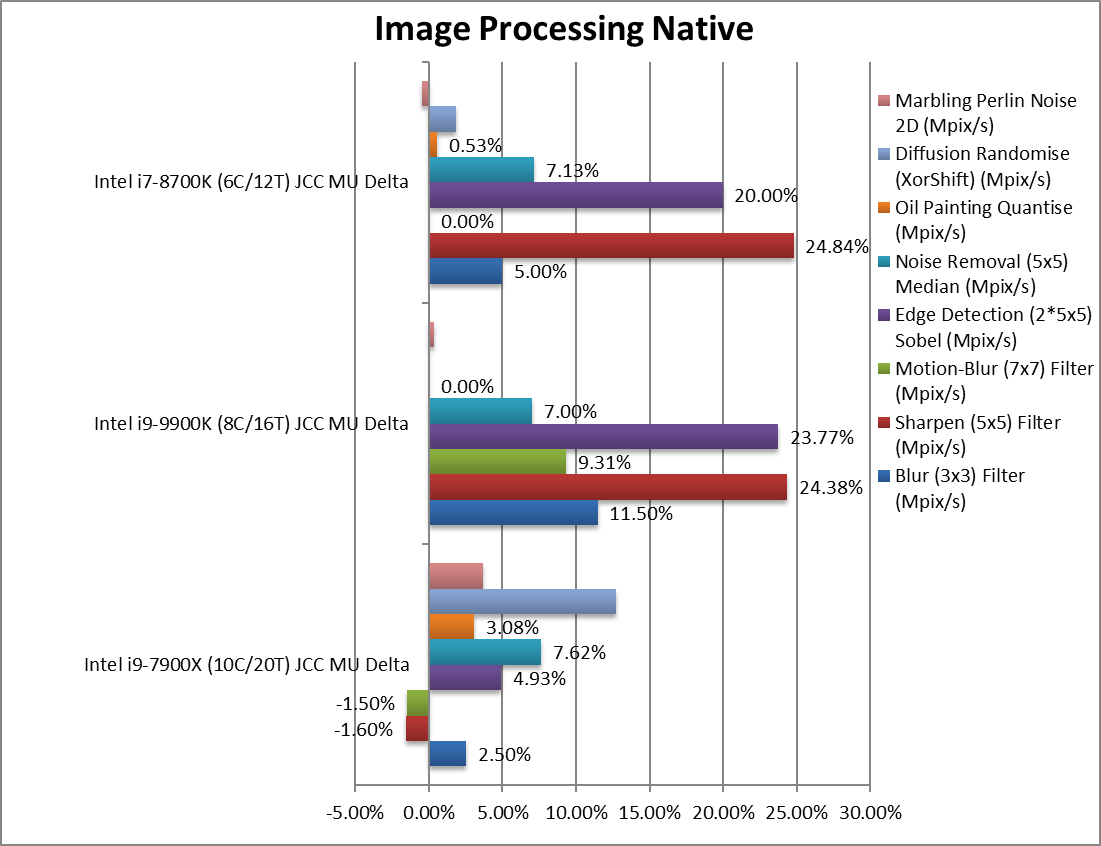
Blur (3×3) Filter (MPix/s) | +2.5% | +11.5% | +5% | In this vectorised integer workload CFL/R gains 5-10% | |
|
Sharpen (5×5) Filter (MPix/s) | -1.6% | +24.38% | +24.84% | Same algorithm but more shared CFL/R zooms to 24%. | |
|
Motion-Blur (7×7) Filter (MPix/s) | -1.5% | +9.31% | 0% | Again same algorithm but even more data shared brings 10% | |
|
Edge Detection (2*5×5) Sobel Filter (MPix/s) | +4.93% | +23.77 | +20% | Different algorithm but still vectorised workload still CFL/R is 20% faster. | |
|
Noise Removal (5×5) Median Filter (MPix/s) | +7.62 | +7% | +7.13% | Still vectorised code TGL is again 50% faster. | |
|
Oil Painting Quantise Filter (MPix/s) | +3.08% | 0% | +0.53% | Not much improvement here. | |
|
Diffusion Randomise (XorShift) Filter (MPix/s) | +12.69% | 0% | +1.85% | With integer workload, SKL-X is 12% faster. | |
|
Marbling Perlin Noise 2D Filter (MPix/s) | +3.69 | +0.33% | -0.44% | In this final test again with integer workload minor changes. | |
| Similar to what we saw before, intrinsic (thus compile) code shows larger gains that hand-optimised assembler code and here again CFL/R gain most while the old SKL-X shows almost no variation. | ||||||
SiSoftware Official Ranker Scores
Final Thoughts / Conclusions
JCC is perhaps a more problematic errata than the other vulnerabilities (“Meltdown”, “Spectre”, etc.) that have affected Intel Core processors – in the sense that it affects all software (both kernel and user mode) and requires re-building everything (programs, libraries, device drivers, etc.) using updated tools. While open-source software is likely to do so – on Windows it is unlikely that all but the very newest versions of Windows (2020+) and actively maintained software (such as Sandra) will be updated; all older software will not.
Server software, either hypervisors, server operating systems (LTS – long term support), server programs (database servers, web-servers, storage servers, etc.) are very unlikely to be updated despite the performance regressions as (re)testing would be required for various certification and compatibility.
As the microcode updates for JCC also include previous mitigations for the older “Meltdown”/”Spectre” vulnerabilities – if you want to patch JCC only you cannot. With microcode updates being pushed aggressively by both BIOS and operating systems it is now much harder not to update. [Some users have chosen to remain on old microcode either due to incompatibilities or performance regression despite the “risks”.]
While older gen 6/7 “Skylake” (SKL/X) do not show much variation, newer gen 8/9/10 “CoffeeLake” (CFL/R) gain the most from new code, especially high-level C/C++ (or intrinsics); hand-written assembler code (suitably patched) does not improve as much. Some gains are in the region of 10-20% (or perhaps this is the loss of the new microcode) thus it makes sense to update any and all software with JCC mitigation if at all possible. [Unfortunately we were unable to test pre-JCC microcode due to the current situation.]
With “real” gen(eration) 10 “Ice Lake” (ICL) and soon-to-be-released gen 11 “Tiger Lake” (TGL) not affected by this erratum, not forgetting the older erratums (“Meltdown”/”Spectre”) – all bringing their own performance degradation – it is perhaps a good time to upgrade. To some extent the new processors are faster simply because they are not affected by all these erratums!
Note: we have also tested the effect the JCC erratum mitigation has (if any) on the competition – namely AMD.
Should you decide to do so, please check out our other articles:
- Benchmarks of JCC Erratum Mitigation – AMD CPUs
- Intel Core Gen11 TigerLake ULV (i7-1165G7) – CPU AVX512 Performance
- Intel Core Gen10 IceLake ULV (i7-1065G7) – CPU AVX512 Performance
- Intel Core Gen10 CometLake ULV (i7-10510U) – CPU Performance
Pingback: Intel Core Gen10 CometLake (i9-10900K) Review & Benchmarks – CPU Performance – SiSoftware
Pingback: Intel Core Gen10 IceLake ULV (i7-1065G7) Review & Benchmarks – CPU AVX512 Performance – SiSoftware