What is “RocketLake”?
It is the desktop/workstation version of the true “next generation” Core (gen 10+) architecture – finally replacing the ageing “Skylake (SKL)” arch and its many derivatives that are still with us (“CometLake (CML)”, etc.). It is a combination of the “IceLake (ICL)” CPU cores launched about a year go and the “TigerLake (TGL)” Gen12 XE graphics cores launched recently.
With the new core we get a plethora of new features – some previously only available on HEDT platform (AVX512 and its many friends), improved L1/L2 caches, improved memory controller and PCIe 4.0 buses. Sadly Intel had to back-port the older ICL (not TGL) cores to 14nm – we shall have to wait for future (desktop) processors “AlderLake (ADL)” to see 10nm on the desktop…
- 14nm+++ improved process (not 10nm)
- Gen12 (Xe-LP) graphics (up to 96 EU in TGL graphics but here 32 EU only)
- Transcode support for all major algorithms (e.g. HEVC/H.265 HDR/10-12bit, AV1 decode)
- PCIe 4.0 (up to 32GB/s with x16 lanes) – 20 (16+4 or 8+8+4) lanes
- Thunderbolt 3 (and thus USB 3.2 2×2 support @ 20Gbps) integrated
While ICL has already greatly upgraded the GP-GPU to gen 11 cores (and more than doubled to 64EU for G7), TGL upgrades them yet again to “XE”-LP gen 12 cores now all the way up to 96EUs. While again most features seem to be geared towards gaming and media (with new image processing and media encoders) – there should be a few new instructions for AI – hopefully provided by a OpenCL extension.
Again there is no FP64 support (!) while FP16 is naturally supported at 2x rate as before. BF16 should also be supported by a future driver. Int32, Int16 performance has reportedly doubled with Int8 now supported and DP4A accelerated.
We do hope to see more GPGPU-friendly features in upcoming versions now that Intel is taking graphics seriously. Perhaps with the forthcoming DG1 discrete graphics
GP-GPU (UHD 750, Xe-LP) Performance Benchmarking
In this article we test GP-GPU core performance; please see our other articles on:
- CPU
- Intel 11th Gen Core RocketLake (i9-11900K) Review & Benchmarks – CPU AVX512 Performance
- Intel 11th Gen Core RocketLake (i7-11700K) Review & Benchmarks – CPU AVX512 Performance
- Intel Core Gen11 TigerLake ULV (i7-1165G7) Review & Benchmarks – CPU AVX512 Performance
- Intel Core Gen10 IceLake ULV (i7-1065G7) Review & Benchmarks – CPU AVX512 Performance
- Memory & Cache
- GP-GPU
Hardware Specifications
We are comparing the middle-range Intel integrated GP-GPUs with previous generation, as well as competing architectures with a view to upgrading to a brand-new, high performance, design.
| Specifications | Intel UHD 750 (32C, RKL RocketLake, i7 11700K) | Intel Iris XE ULV (96C, TGL TigerLake, i7 1165G7) | Intel Iris Plus ULV (64C, ICL IceLake, i7 1065G7) | Intel UHD 630 (24C, CFL-R CoffeeLake, i9 9900K) | Comments | |
| Arch / Chipset | EV12 / G1 | EV12 / G7 | EV11 / G7 | EV9.5 / GT2 | Gen 12 graphics – the latest. | |
| Cores (CU) / Threads (SP) | 256 / 32 [+33%] | 768 / 96 | 64 / 512 | 24 / 192 | 33% more cores vs. CFL. | |
| Speed (Min-Turbo) |
1.3GHz [+8%] |
1.2GHz | 1.1GHz | 1.2GHz | Turbo speed has slightly increased. | |
| Power (TDP) | 125W [+25%] | 28W | 15W | 95W | TDP has increased 25% over CFL | |
| ROP / TMU | / | 24 / 48 | 16 / 32 | 8 / 16 | ROPs and TMUs likely increased. | |
| Shared Memory |
64kB |
64kB | 64kB | 64kB | Same shared memory. | |
| Constant Memory |
3.2GB | 3.2GB | 3.2GB | 3.2GB | No dedicated constant memory but large. | |
| Global Memory | 2x DDR4 3200Mt/s 128-bit |
2x LP-DDR4X 4267Mt/s 128-bit |
2x LP-DDR4X 3733Mt/s 128-bit | 2x DDR4-3000Mt/s 128-bit | Supports faster DDR4 memory. | |
| Memory Bandwidth |
42GB/s | 42GB/s | 58GB/s | 42GB/s | Highest (possible) bandwidth ever | |
| L1 Caches | 64kB | 64kB | 16kB | 16kB | L1 is much larger. | |
| L3 Cache | 3.8MB | 3.8MB | 3MB | 512MB | L3 has modestly increased. | |
| Maximum Work-group Size |
256×256 | 256×256 | 256×256 | 256×256 | Same workgroup size | |
| FP64/double ratio |
No! | No! | No! | Yes, 1/16x | No FP64 support in current drivers! | |
| FP16/half ratio |
2x | 2x | 2x | 2x | Same 2x ratio | |
| Price / RRP (USD) |
$399 [-17%] |
n/a | n/a | $479 | Keen price, 17% lower! | |
Disclaimer
This is an independent review (critical appraisal) that has not been endorsed nor sponsored by any entity (e.g. Intel, etc.). All trademarks acknowledged and used for identification only under fair use.
And please, don’t forget small ISVs like ourselves in these very challenging times. Please buy a copy of Sandra if you find our software useful. Your custom means everything to us!
Native OpenCL Performance
We are testing both OpenCL performance using the latest SDK / libraries / drivers from both Intel and competition.
Note: The results were re-run with the latest Intel Graphics drivers (27.20.100.9466) of 14th April 2021 that have fixed all known regressions.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest Intel graphics drivers. Turbo / Boost was enabled on all configurations.
| Processing Benchmarks | Intel UHD 750 (32C, RKL RocketLake, i7 11700K) | Intel Iris XE ULV (96C, TGL TigerLake, i7 1165G7) | Intel Iris Plus ULV (64C, ICL IceLake, i7 1065G7) | Intel UHD 630 (24C, CFL-R CoffeeLake, i9 9900K) | Comments | |
 |
||||||
 |
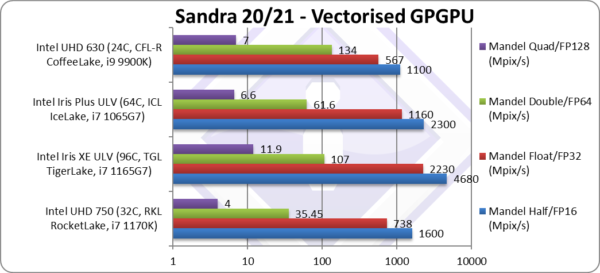
Mandel FP16/Half (Mpix/s) | 1,600 [+45%] | 4,680 | 2,300 | 1,100 | Xe is 43% faster than EV9.5 |
|
Mandel FP32/Single (Mpix/s) | 738 [+30%] | 2,230 | 1,160 | 567 | Standard FP32 is just 28% faster. |
|
Mandel FP64/Double (Mpix/s) | 35.45* [1/4x] | 107* | 61.6* | 134 | Without native FP64 support Xe is 1/4 the speed of EV9.5. |
|
Mandel FP128/Quad (Mpix/s) | 4* [1/2x] | 11.9* | 6.6* | 7 | Emulated FP128 is 1/2x speed. |
| Starting off, we see decent scaling with RKL’s XE32 28-43% faster than old EV9.5. Despite the higher TDP and still at 14nm it is still a decent improvement.
As with ICL and TGL, the lack of FP64 native support means any 64-bit floating point is 1/2-1/4x slower than even the ancient EV9.5 of CFL. For FP64 workloads – you’ll just have to use the CPU. What is strange is that Intel was the 1st to provide native 64-bit floating-point in consumer hardware and now it has removed it? * Emulated FP64 through FP32. |
||||||
 |
||||||
 |
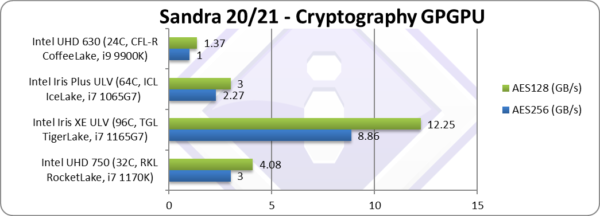
Crypto AES-256 (GB/s) | 3 [+3x] | 8.86 | 2.27 | 1 | Integer performance is 3x faster than EV9.5. |
|
Crypto AES-128 (GB/s) | 4.1 [+3x] | 12.25 | 3 | 1.37 | Nothing much changes when changing to 128bit. |
 |
||||||
|
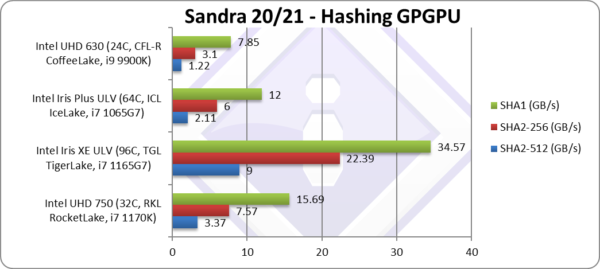
Crypto SHA2-256 (GB/s) | 7.57 [+2.4x] | 22.39 | 6 | 3.1 | Xe is over 2x faster than EV9.5. |
|
Crypto SHA1 (GB/s) | 15.69 [+2x] | 34.57 | 12 | 7.85 | With 128-bit Xe is 70% faster. |
|
Crypto SHA2-512 (GB/s) | 3.37 [+2.76x] | 9 | 2.11 | 1.22 | 64-bit integer workload is also stellar. |
| With integer workloads, Xe32 is finally clearly faster than EV9.5 of CFL – as much as 3x and at least 70% in all tests. That is a pretty impressive performance, similar to what we saw in our TGL review – using Xe96. Naturally with just 32 EU it cannot reach the same performance but the result is impressive still. | ||||||
 |
||||||
 |
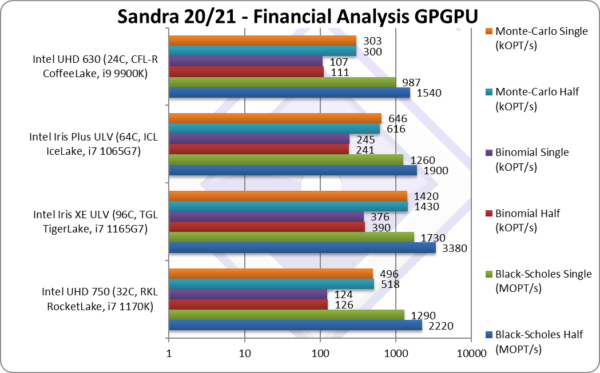
Black-Scholes float/FP16 (MOPT/s) | 2,222 [+44%] | 3,380 | 1,900 | 1,540 | With FP16 we have 44% improvement. |
|
Black-Scholes float/FP32 (MOPT/s) | 1,290 [+31%] | 1,730 | 1,260 | 987 | With FP32 we see a 31% improvement |
|
Binomial half/FP16 (kOPT/s) | 126 [+14%] | 390 | 241 | 111 | Binomial uses thread shared data thus stresses the memory system. |
|
Binomial float/FP32 (kOPT/s) | 124 [+16%] | 376 | 245 | 107 | With FP32, Xe32 is just 16% faster. |
|
Monte-Carlo half/FP16 (kOPT/s) | 518 [+73%] | 1,430 | 616 | 300 | Monte-Carlo also uses thread shared data but read-only. |
|
Monte-Carlo float/FP32 (kOPT/s) | 496 [+64%] | 1,420 | 646 | 303 | With FP32 code Xe32 is 64% faster. |
| For financial FP32/FP16 workloads, Xe32 is sometimes a lot faster than old EV9.5 – and now the regressions have been fixed by the latest drivers. Elsewhere Xe32 is 5-64% faster than EV9.5 which is again pretty impressive – though naturally cannot match TGL’s 96EU GP-GPU.
No point to test or mention lack of native FP64 again – it’s not there. You are not going to be running 64-bit financial workloads on this GP-GPU. |
||||||
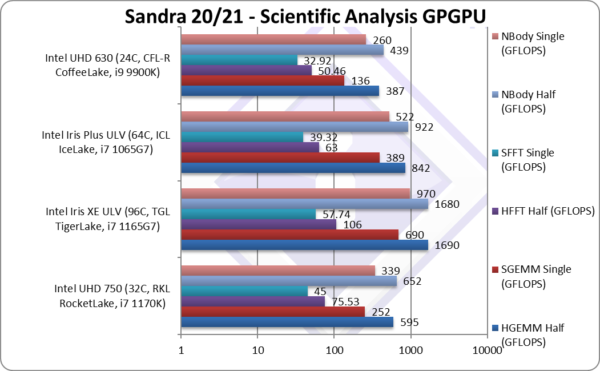 |
||||||
 |
HGEMM (GFLOPS) float/FP16 | 595 [+54%] | 1,690 | 842 | 387 | Xe32 starts well with 54% improvement. |
|
SGEMM (GFLOPS) float/FP32 | 252 [+85%] | 690 | 389 | 136 | With FP32, Xe32 is 85% faster! |
|
HFFT (GFLOPS) float/FP16 | 75.53 [+50%] | 106 | 63 | 50.46 | We see a 50% improvement here. |
|
SFFT (GFLOPS) float/FP32 | 45 [+37%] | 57.74 | 39.32 | 32.92 | With FP32, Xe32is 37% faster. |
|
HNBODY (GFLOPS) float/FP16 | 652 [+49%] | 1,680 | 922 | 439 | Xe32 is 50% faster here. |
|
SNBODY (GFLOPS) float/FP32 | 339 [+30%] | 970 | 522 | 260 | With FP32, Xe32 is 30% faster. |
| On scientific algorithms (FP32 and FP16), Xe32 does much better and manages to be 30-63% faster than old EV9.5 of RKL. Again, all regressions have been fixed by the latest drivers which is very useful.
Shall we mention lack of FP64 again? No we won’t. |
||||||
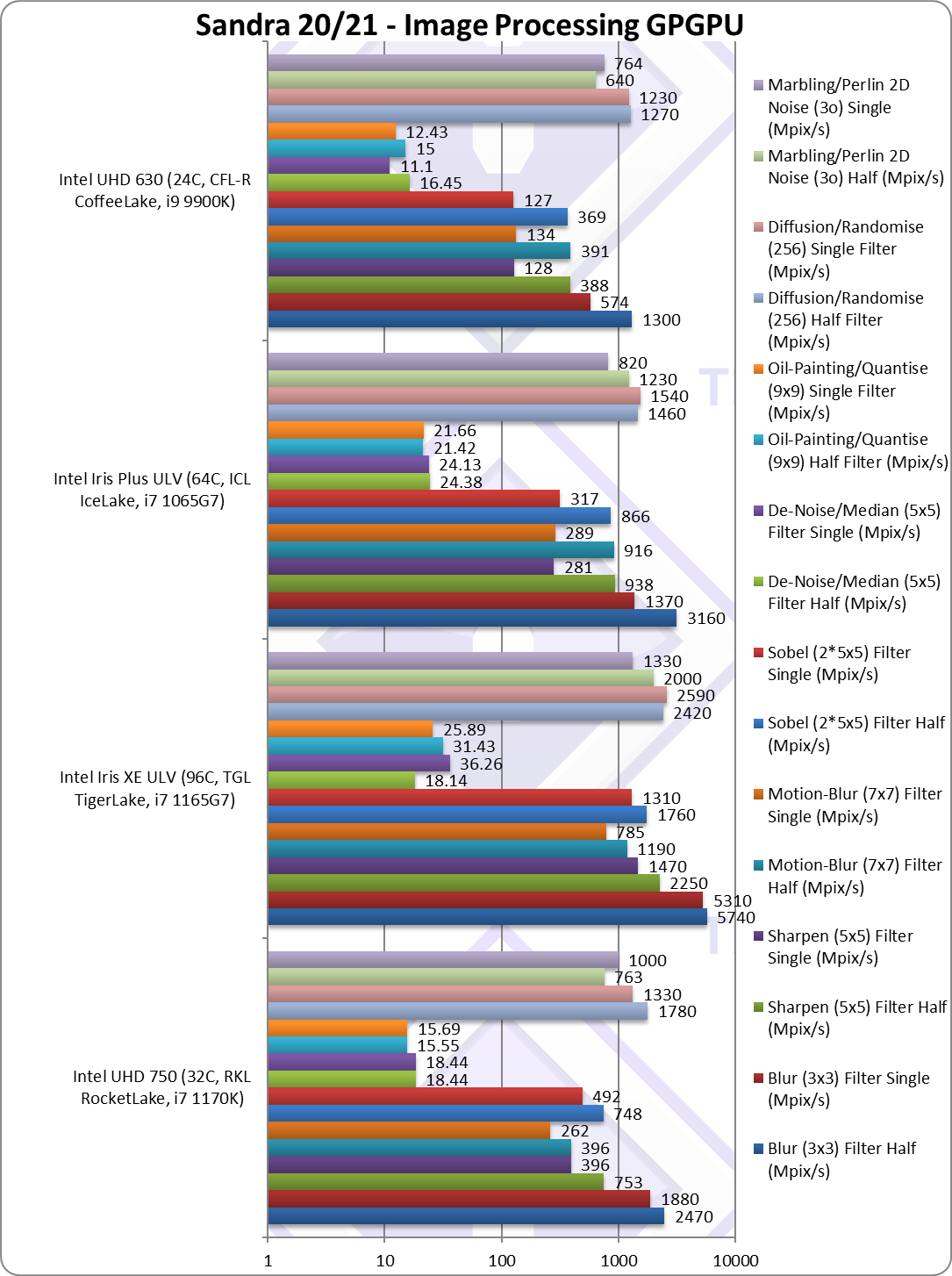 |
||||||
 |
Blur (3×3) Filter single/FP16 (MPix/s) | 2,470 [+90%] | 5,740 | 3,160 | 1,300 | FP16 is almost 2x faster. |
|
Blur (3×3) Filter single/FP32 (MPix/s) | 1,880 [+3.28x] | 5,310 | 1,370 | 574 | In this 3×3 convolution algorithm, Xe32 is over 3x faster! |
|
Sharpen (5×5) Filter single/FP16 (MPix/s) | 753 [+94%] | 2,250 | 938 | 388 | Again FP16 is 2x faster. |
|
Sharpen (5×5) Filter single/FP32 (MPix/s) | 396 [+3.1x] | 1,470 | 281 | 128 | Same algorithm but more shared data, Xe32 is 3.1x faster. |
|
Motion Blur (7×7) Filter single/FP16 (MPix/s) | 496 [+27%] | 1,190 | 916 | 391 | FP16 is just 27% faster. |
|
Motion Blur (7×7) Filter single/FP32 (MPix/s) | 262 [+2x] | 785 | 289 | 134 | With even more data Xe32 is 2x faster. |
|
Edge Detection (2*5×5) Sobel Filter single/FP16 (MPix/s) | 748 [+2x] | 1,760 | 866 | 369 | FP16 is over 2x faster. |
|
Edge Detection (2*5×5) Sobel Filter single/FP32 (MPix/s) | 492 [+3.87x] | 1,310 | 317 | 127 | Still convolution but with 2 filters – 3.8x faster. |
|
Noise Removal (5×5) Median Filter single/FP16 (MPix/s) | 18.44 [+12%] | 18.14 | 24.38 | 16.45 | FP16 brings just 12% improvement. |
|
Noise Removal (5×5) Median Filter single/FP32 (MPix/s) | 18.44 [+66%] | 36.26 | 24.13 | 11.1 | Different algorithm Xe32 66% faster. |
|
Oil Painting Quantise Filter single/FP16 (MPix/s) | 15.55 [+4%] | 31.43 | 21.42 | 15 | FP16 is just 4% faster. |
|
Oil Painting Quantise Filter single/FP32 (MPix/s) | 15.69 [+26%] | 25.89 | 21.66 | 12.43 | Without major processing, Xe32 is 26% faster. |
|
Diffusion Randomise (XorShift) Filter single/FP16 (MPix/s) | 1,780 [+40%] | 2,420 | 1,460 | 1,270 | FP16 is 40% faster. |
|
Diffusion Randomise (XorShift) Filter single/FP32 (MPix/s) | 1,330 [+8%] | 2,590 | 1,540 | 1,230 | This algorithm is 64-bit integer heavy and Xe32 is 8% faster. |
|
Marbling Perlin Noise 2D Filter single/FP16 (MPix/s) | 763 [+20%] | 2,000 | 1,230 | 640 | FP16 is 20% faster. |
|
Marbling Perlin Noise 2D Filter single/FP32 (MPix/s) | 1,000 [+31%] | 1,330 | 820 | 764 | One of the most complex and largest filters, Xe32 is 31% faster. |
| For image processing tasks, Xe32 seems to do best, with up to 4x better performance over old EV9.5; we saw similar improvement in TGL GP-GPU review. In any case for such tasks, upgrading to Xe32 will give you a huge boost. (fortunately no FP64 processing here) | ||||||
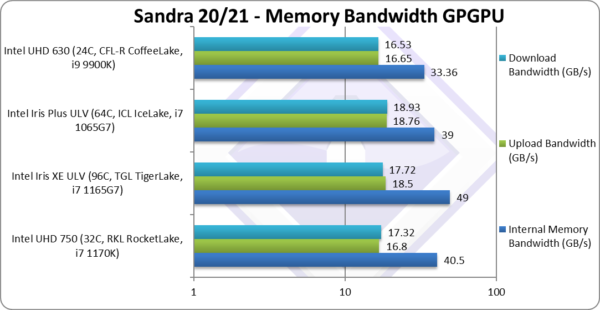 |
||||||
 |
Internal Memory Bandwidth (GB/s) | 40.5 [+21%] | 49 | 39 | 33.36 | Xe32 extracts 20% more bandwidth. |
|
Upload Bandwidth (GB/s) | 16.8 [+1%] | 18.5 | 18.76 | 16.65 | Uploads are same speed. |
|
Download Bandwidth (GB/s) | 17.32 [+5%] | 17.72 | 18.93 | 16.53 | Download bandwidth is 5% better. |
| It seems Xe32 really benefits from faster physical memory, with DDR4 unable to match high-speed LP-DDR4X despite its low power, but does extract higher bandwidth from the same DDR4-3200 memory. | ||||||
SiSoftware Official Ranker Scores
- 11th Gen Intel Core i9-11900K (8C / 16T, 5.3GHz)
- 11th Gen Intel Core i7-11700K (8C / 16T, 3.6GHz)
- 11th Gen Intel Core i7-11700 (8C / 16T, 2.5GHz)
- 11th Gen Intel Core i5-11600 (6C / 12T, 4.8GHz)
Final Thoughts / Conclusions
Summary: Recommended (~15% improvement over old EV9.5): 8/10
Note: as the latest driver has fixed all the regressions, we have updated the score up. Our only regret is that there are just 32 EUs.
Once again Intel seems to be taking graphics seriously: for the 2nd time in a row we have a major graphics upgrade with Xe with big upgrades in EV cores (count), performance and bandwidth. It is lucky RKL has ended up with 14nm+++ Xe Gen 12 graphics cores and not Gen 11. As we saw in our TGL review, it can make a big difference.
But unlike top-end TGL APUs with 96 EUs, here we have just 32 EUs which despite much higher TDP (though at 14nm+++ not 10nm) cannot perform miracles, but ignoring a few preformance regressions it generally ends up much faster than old EV9.5 of CFL/CML – but all in all it ends up just 15% faster which is a pity.
However, this is still a core aimed at gamers and it does not provide much for GP-GPU; the improved integer performance is very much welcome – 3-times better (!) but few and specific instructions for AI only. Lack of FP64 makes it unsuitable for high-precision financial and scientific workloads; something that the old EV7-9 cores could do reasonably well (all things considered).
For integrated graphics, this is not a problem – not many people would expect integrated GPU core to run compute-heavy workloads; however, the lack of FP64 support is still jarring considering we’ve been used to having it in just about all other graphics architectures – including all the old Intel architectures.
It does seem that Xe32 and thus RKL like TGL before it really needs faster memory to perform much better and with improved drivers and faster memory we will see much better performance. These days Intel is releasing updated drivers regularly, fixing issues and adding features thus the future looks pretty bright.
Summary: Recommended 7/10
Please see our other articles on:
- CPU
- Intel 11th Gen Core RocketLake (i9-11900K) Review & Benchmarks – CPU AVX512 Performance
- Intel 11th Gen Core RocketLake (i7-11700K) Review & Benchmarks – CPU AVX512 Performance
- Intel Core Gen11 TigerLake ULV (i7-1165G7) Review & Benchmarks – CPU AVX512 Performance
- Intel Core Gen10 IceLake ULV (i7-1065G7) Review & Benchmarks – CPU AVX512 Performance
- Memory & Cache
- GP-GPU
Disclaimer
This is an independent review (critical appraisal) that has not been endorsed nor sponsored by any entity (e.g. Intel, etc.). All trademarks acknowledged and used for identification only under fair use.
And please, don’t forget small ISVs like ourselves in these very challenging times. Please buy a copy of Sandra if you find our software useful. Your custom means everything to us!